
De plus en plus fréquemment, nous entendons parler de la recherche sémantique et de nouvelles façons de la mettre en œuvre. Dans la dernière version d'OpenSearch (2.11), la recherche sémantique à travers des vecteurs creux a été introduite. Mais que signifie vecteur creux? Comment cela diffère-t-il d'une matrice dense? Tentons de clarifier cela dans cet article.

Si vous êtes familier avec les moteurs de recherche conventionnels et les technologies comme OpenSearch et Elasticsearch, vous avez probablement rencontré tf-idf et bm-25, deux algorithmes exploitant des structures creux pour la représentation des documents et le calcul de la pertinence. Pour simplifier l’explication des structures creux, considérons une base de données avec trois documents :
Représentons ces documents dans une matrice d’incidence :
| quick | brown | fox | jumps | lazy | dog | sleeps | the | and | a | |
|---|---|---|---|---|---|---|---|---|---|---|
| Document 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 |
| Document 2 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 1 |
| Document 3 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 2 | 1 | 0 |
En utilisant la même matrice, nous pouvons calculer la matrice de fréquence à l’aide de la formule :
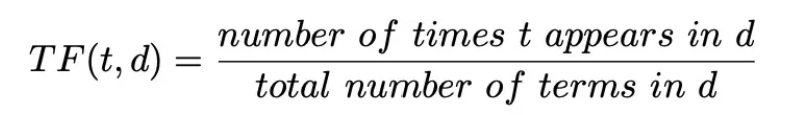
| quick | brown | fox | jumps | lazy | dog | sleeps | the | and | a | |
|---|---|---|---|---|---|---|---|---|---|---|
| Document 1 | 0.25 | 0.25 | 0.25 | 0.25 | 0 | 0 | 0 | 0.25 | 0 | 0 |
| Document 2 | 0 | 0 | 0 | 0 | 0.33 | 0.33 | 0.33 | 0.33 | 0 | 0.33 |
| Document 3 | 0 | 0.33 | 0.33 | 0 | 0.33 | 0.33 | 0 | 0.67 | 0.33 | 0 |
Enfin, en appliquant la formule :
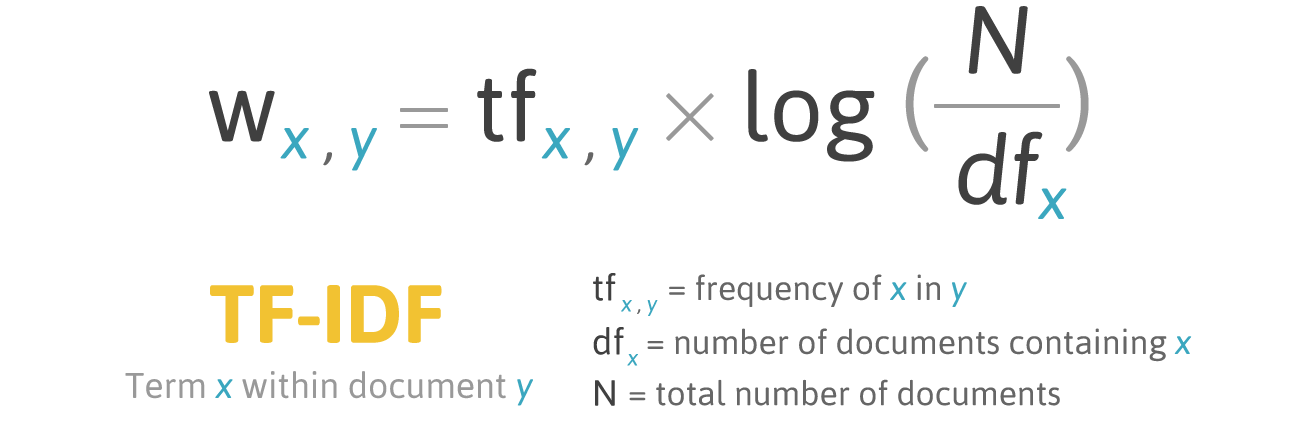
Nous pouvons visualiser la matrice utilisée dans un algorithme tf-idf, qui est utilisé pour calculer la pertinence :
| quick | brown | fox | jumps | lazy | dog | sleeps | the | and | a | |
|---|---|---|---|---|---|---|---|---|---|---|
| Document 1 | 0.044 | 0.044 | 0.044 | 0.146 | 0 | 0 | 0 | 0 | 0 | 0 |
| Document 2 | 0 | 0 | 0 | 0 | 0.058 | 0.058 | 0.195 | 0 | 0 | 0.058 |
| Document 3 | 0 | 0.058 | 0.058 | 0 | 0.058 | 0.058 | 0 | 0 | 0.058 | 0 |
Vous avez peut-être remarqué, comme illustré dans la matrice ci-dessus, que les valeurs sont principalement concentrées autour de quelques entrées non nulles, tandis que la majorité reste à zéro. Cette concentration de valeurs non nulles au milieu d’une mer de zéros caractérise ce que l’on appelle les “vecteurs épars”.
La rareté de ces vecteurs permet un stockage et un calcul plus efficaces : elle réduit la redondance, car seuls les éléments non nuls doivent être stockés, ce qui conduit à des structures de données plus compactes. Cette efficacité est particulièrement bénéfique lors du travail avec de grands ensembles de données, car elle permet des calculs plus rapides et réduit les besoins en mémoire.
En utilisant des vecteurs creux, nous avons essentiellement représenté l’essence de chaque document en utilisant un ensemble de valeurs numériques, dont une partie importante est égale à 0.
Les vecteurs denses nous permettront de faire la même chose, sans avoir recours aux 0. Dans les vecteurs denses, chaque document est représenté par un vecteur où chaque valeur est comprise entre 0 et 1. Chaque valeur représentera une caractéristique de notre document.
Plongeons dans le fonctionnement des vecteurs denses avec un exemple. Nous avons quelques documents, chacun représentant un animal différent. Pour décrire chaque animal, nous utiliserons certaines caractéristiques communes. Par exemple, la taille, l’amabilité et l’intelligence.
Pour chaque caractéristique, nous pouvons attribuer une valeur de 0 à 1, où 0 signifie moins et 1 plus. Par exemple, un chat est un animal assez amical, de petite taille et extrêmement intelligent (bien qu’il aime dormir tout le temps).
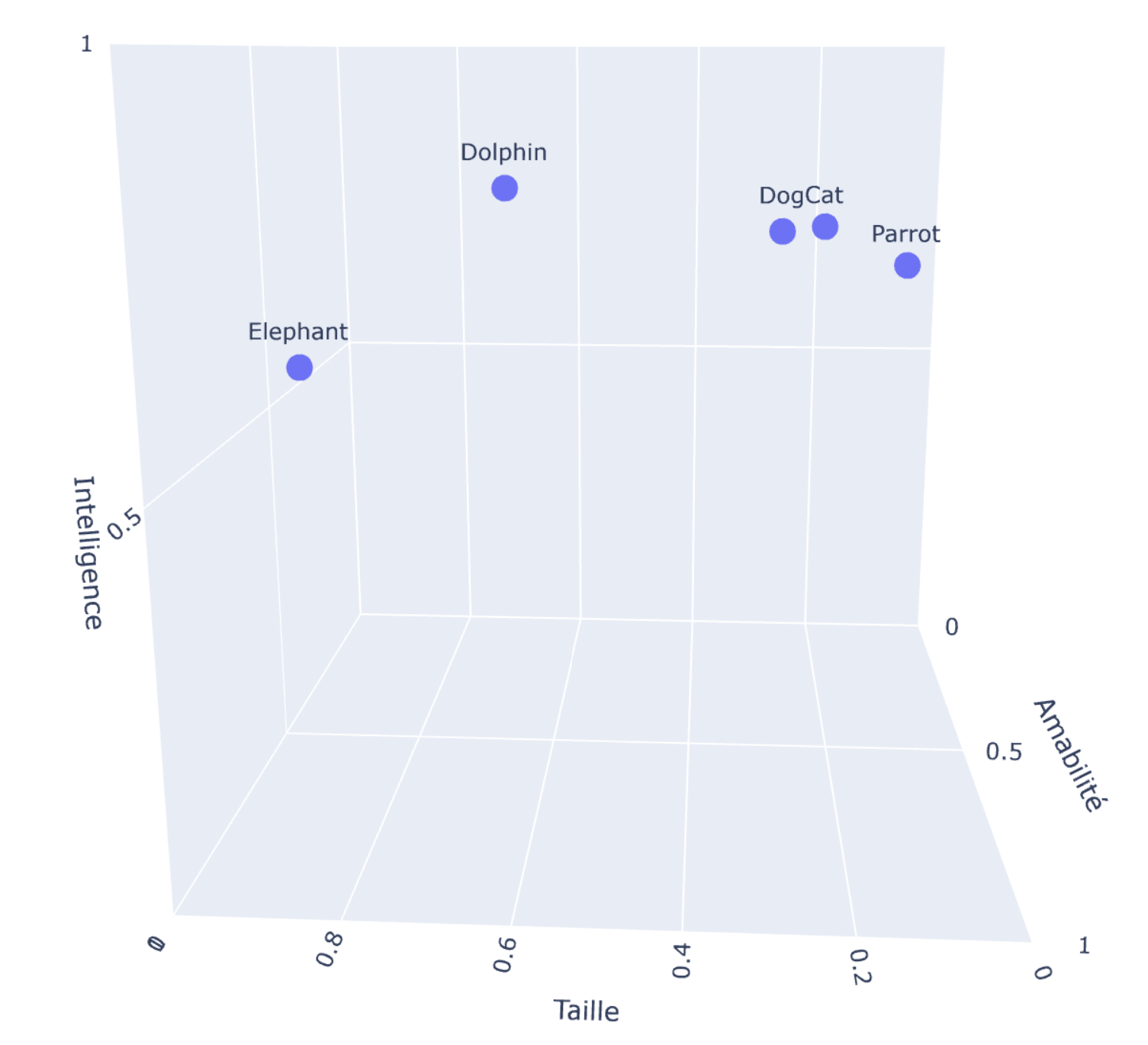
Ainsi, nous pouvons transformer notre chat et tous les animaux de notre collection en vecteurs :
| Animal | Taille | Amabilité | Intelligence |
|---|---|---|---|
| Chat | 0.25 | 0.85 | 0.80 |
| Chien | 0.30 | 0.90 | 0.80 |
| Éléphant | 0.90 | 0.70 | 0.60 |
| Dauphin | 0.60 | 0.95 | 0.85 |
| Perroquet | 0.15 | 0.80 | 0.75 |
Comme vous l’avez peut-être remarqué, nous avons représenté la collection à l’aide de vecteurs sans adopter de valeurs 0. De plus, chaque document est caractérisé par des caractéristiques spécifiques, ce qui permet des comparaisons faciles. En effet, nous pouvons facilement représenter cet espace vectoriel tridimensionnel à l’aide d’un graphique 3D.
Le processus de création de vecteurs denses est généralement réalisé à l’aide de modèles spécifiques. Ces modèles génèrent des vecteurs de plusieurs dimensions, souvent dans les centaines. Alors que l’exemple d’animal était relativement simple avec un vecteur tridimensionnel, imaginez travailler avec un vecteur de 784 dimensions. Cette complexité suggère que la génération de ces vecteurs peut être chronophage et nécessiter plus d’espace que ce que l’on rencontre généralement avec des vecteurs creux.
En recherche vectorielle ou sémantique, nous comparons essentiellement notre base de données vectorielle à un vecteur de requête. Le vecteur de requête est essentiellement notre requête transformée en un vecteur.
La comparaison entre le vecteur de requête et la base de données peut se faire à travers différentes fonctions mathématiques, telles que la similarité cosinus ou la distance du produit scalaire. Les documents les plus similaires à notre vecteur de requête sont les documents les plus pertinents, et, normalement, les documents que nous recherchons.
Si vous souhaitez en savoir plus sur le fonctionnement de la recherche vectorielle et comment la mettre en œuvre, vous voudrez peut-être jeter un coup d'œil à Exploration de la recherche vectorielle avec JINA. Aperçu et guide et Plongée dans le traitement du langage naturel avec le stack Elastic.
La recherche sémantique peut également être réalisée à travers des vecteurs creux, grâce à une technique appelée “Expansion de termes”. L’expansion de termes consiste à élargir la représentation d’un document en incorporant des termes supplémentaires pertinents qui peuvent capturer le sens du document. Ces termes élargis sont indexés comme s’ils faisaient initialement partie du document. Dans ce contexte, des modèles d’apprentissage automatique tels que “elser” d’Elasticsearch ou le Neural Encoder d’Amazon pour OpenSearch peuvent être utilisés pour une expansion de termes efficace.
Voyons comment cela fonctionne, une fois de plus, à travers des exemples :
Comme nous l’avons fait précédemment, considérons ces phrases :
et leur matrice d’incidence :
| quick | brown | fox | jumps | lazy | dog | sleeps | the | and | a | |
|---|---|---|---|---|---|---|---|---|---|---|
| Document 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 |
| Document 2 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 1 |
| Document 3 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 2 | 1 | 0 |
L’expansion de termes vise à associer de nouveaux mots pertinents à chaque document. Par exemple, le terme “rapide” peut être étendu en utilisant différents synonymes, tels que “fast” ou “swift”. Cela peut être fait pour chaque terme et pour chaque phrase de notre base de données.
Par exemple :
ce qui aboutira à une nouvelle matrice d’incidence
| quick | fast | swift | brown | fox | animal | jumps | lazy | dog | sleeps | the | and | a | … | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Document 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | — |
| Document 2 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | — |
| Document 3 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 2 | 1 | 0 | — |
Maintenant, si nous recherchons ‘naps’, nous récupérerons le deuxième document où ‘A lazy dog sleeps.’
Tout comme dans la recherche sémantique avec vecteurs denses, la recherche sémantique avec vecteurs creux peut également utiliser le modèle d’apprentissage automatique pendant la phase de recherche pour étendre notre requête. Dans ce cas, il s’agit des bi-codeurs dans la recherche avec vecteurs denses. Si nous utilisons l’expansion de termes uniquement pendant l’indexation, nous sommes en mode “only-document”. Cette deuxième solution est beaucoup plus rapide car il n’y a pas d’expansion de termes à l’exécution.
La recherche avec vecteurs creux a trois grands avantages par rapport à la recherche avec vecteurs denses :
Dans cette exploration des vecteurs creux et denses, nous avons plongé dans les aspects fondamentaux des moteurs de recherche. Nous avons couvert l’utilisation traditionnelle de vecteurs creux dans des algorithmes tels que tf-idf et bm-25, ainsi que des techniques plus modernes impliquant à la fois des vecteurs denses et creux pour la recherche sémantique.
Il est crucial de se rappeler que le choix entre la recherche par mot-clé et la recherche sémantique dépend des exigences spécifiques d’une application donnée, et la recherche vectorielle n’est pas toujours la solution la plus efficace. De plus, décider entre des vecteurs creux et denses peut être complexe et nécessite une analyse approfondie des exigences.
En conclusion, le paysage de la recherche d’informations continue d'évoluer. Comprendre les avantages des approches avec vecteurs creux et denses est essentiel pour construire des systèmes de recherche efficaces et évolutifs, et nous espérons que cet article a contribué à clarifier chaque différence.