
Ces derniers temps, on entend de plus en plus parler de l'ingénierie des prompts. Mais qu'est-ce que cette technique exactement ? Quand et comment pouvons-nous l'utiliser ?
L’ingénierie des prompts est l’une de ces techniques qui attire de plus en plus l’attention. Sans surprise, l’ingénierie des prompts est étroitement liée à la technologie qui transforme de plus en plus nos vies : les grands modèles de langage. Des technologies comme Gemini et ChatGPT sont de plus en plus utilisées par le grand public, en partie grâce à leur intégration dans des outils quotidiens (comme les moteurs de recherche tels que Bing ou les assistants virtuels sur nos smartphones, comme l’iPhone 16).
Cependant, lorsque vous disposez d’un outil aussi puissant, il est crucial de savoir comment l’utiliser efficacement. L’ingénierie des prompts est une technique qui nous permet de façonner un grand modèle de langage pour répondre à nos besoins.
Google la définit comme “l’art et la science de concevoir des prompts pour guider les modèles d’IA vers la génération de réponses souhaitées”. Mais qu’est-ce qu’un prompt ?
Le prompt est essentiellement les instructions que nous donnons à un grand modèle de langage, exprimées en langage écrit ou parlé. Puisque le LLM n’est pas humain, nous devons suivre certaines “directives verbales” pour nous assurer qu’il nous comprend correctement. Après tout, le LLM adhère à un principe fondamental de l’informatique et des données :
“Garbage in, garbage out."
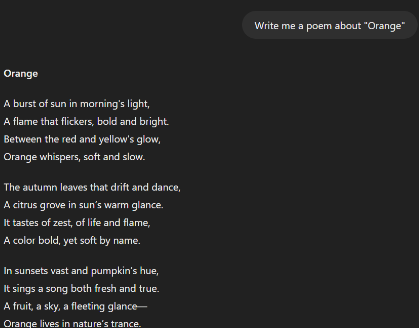
Si nous ne nous exprimons pas correctement, le LLM peut ne pas nous comprendre. Pire encore, si nous ne sommes pas conscients des limitations du LLM, il pourrait nous donner des réponses incorrectes ou générer un contenu trompeur. Dans cet exemple, demandons un poème sur “Orange”. S’agit-il de l’entreprise ? Du fruit ? De la couleur ? De la ville française ? Le LLM ne peut pas lire dans nos pensées (pas encore).
Le LLM peut gérer un éventail impressionnant de tâches, même sans exemples. Que ce soit pour générer une histoire, répondre à une question ou traduire une phrase, les LLM sont assez capables de comprendre par eux-mêmes.
Les LLM sont étonnamment efficaces pour les tâches en zéro-shot car ils ont été entraînés sur d'énormes ensembles de données, leur permettant de tirer parti de schémas généraux. Cependant, même s’ils peuvent gérer une large variété de demandes, le prompting en zéro-shot manque parfois de précision ou de clarté—surtout si la tâche est complexe ou spécifique.
Maintenant, imaginez que vous organisez une fête pour votre ami marocain. Vous demandez à votre LLM préféré une liste des cinq plats marocains les plus populaires. Le modèle répond avec une liste de plats traditionnels comme le couscous et le tagine. C’est un bon début, mais il manque quelque chose. Vous espériez plus de détails, comme les ingrédients, le niveau de difficulté, et si les plats sont végétaliens, végétariens ou autre.
Dans ce cas, le prompting en zéro-shot vous donne une réponse générale, mais il manque la profondeur dont vous avez besoin. C’est là qu’intervient le prompting en few-shot—en donnant au modèle quelques exemples du type de réponse que vous recherchez, vous pouvez le guider vers des résultats plus détaillés et pertinents.
Veuillez lister les cinq plats marocains les plus populaires, en incluant les ingrédients, le niveau de difficulté, et si chaque plat est végétalien ou végétarien.
Voici un format d'exemple :
Couscous
Ingrédients : Semoule, légumes, agneau ou poulet
Difficulté : Modérée
Type : Peut être préparé végétarien ou avec de la viande
En fournissant quelques exemples dès le départ, le LLM adhère à la structure spécifique que vous avez fournie, minimisant les hallucinations et générant des résultats plus pertinents, détaillés et précis.
Parfois, les techniques en 0-shot et en n-shot peuvent ne pas suffire. Parfois, notre modèle peut avoir besoin de plus de temps pour “penser” et élaborer la réponse correcte plutôt que de générer de mauvaises conclusions. C’est souvent le cas des problèmes mathématiques.
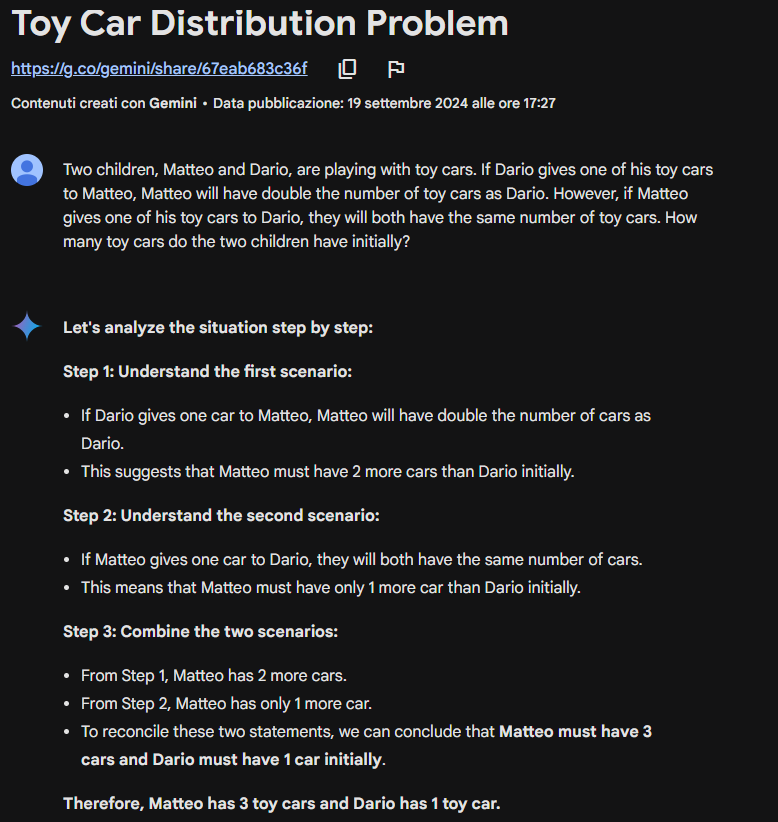
La technique de chaîne de pensée encourage le modèle à décomposer son processus de réflexion et à travailler à travers chaque étape du raisonnement plutôt que de produire une réponse en une seule étape. Cette approche structurée améliore considérablement la capacité du modèle à parvenir à la solution correcte, surtout pour les problèmes nécessitant une compréhension plus profonde ou des étapes logiques.
De plus, la technique de chaîne de pensée peut être appliquée de différentes manières, tout comme d’autres méthodes de prompting. Elle a des versions en zéro-shot et en few-shot :
-Dans la version zéro-shot, le modèle est simplement invité à penser étape par étape, mais sans exemples spécifiques.
-Dans la version few-shot, le modèle reçoit quelques exemples de la manière de décomposer les problèmes en étapes. En observant ces exemples, le modèle peut mieux comprendre comment structurer son raisonnement, augmentant ainsi l’exactitude et la fiabilité dans des tâches plus complexes ou inconnues.

Dans cet exemple, la chaîne de pensée en zéro-shot a suffi au modèle pour donner une réponse correcte. Dans certains cas, ni la CoT ne peut être suffisante…
En effet, bien que la CoT encourage le modèle à réfléchir étape par étape, il existe un problème potentiel : puisque chaque étape est basée sur la précédente, le modèle peut parfois perdre de vue la vue d’ensemble.
Ce problème est connu sous le nom de Naive Greedy Decoding, où le modèle prend des décisions localement, se concentrant trop étroitement sur l'étape immédiate sans tenir compte du contexte plus large, ce qui peut entraîner des réponses incohérentes ou incorrectes.
L’auto-cohérence offre une solution à ce problème. Au lieu de se fier à un seul passage de raisonnement (qui peut être erroné en raison d’une dépendance excessive aux étapes précédentes), l’auto-cohérence génère plusieurs chemins de raisonnement indépendants, puis sélectionne la réponse la plus cohérente ou la plus commune parmi eux.
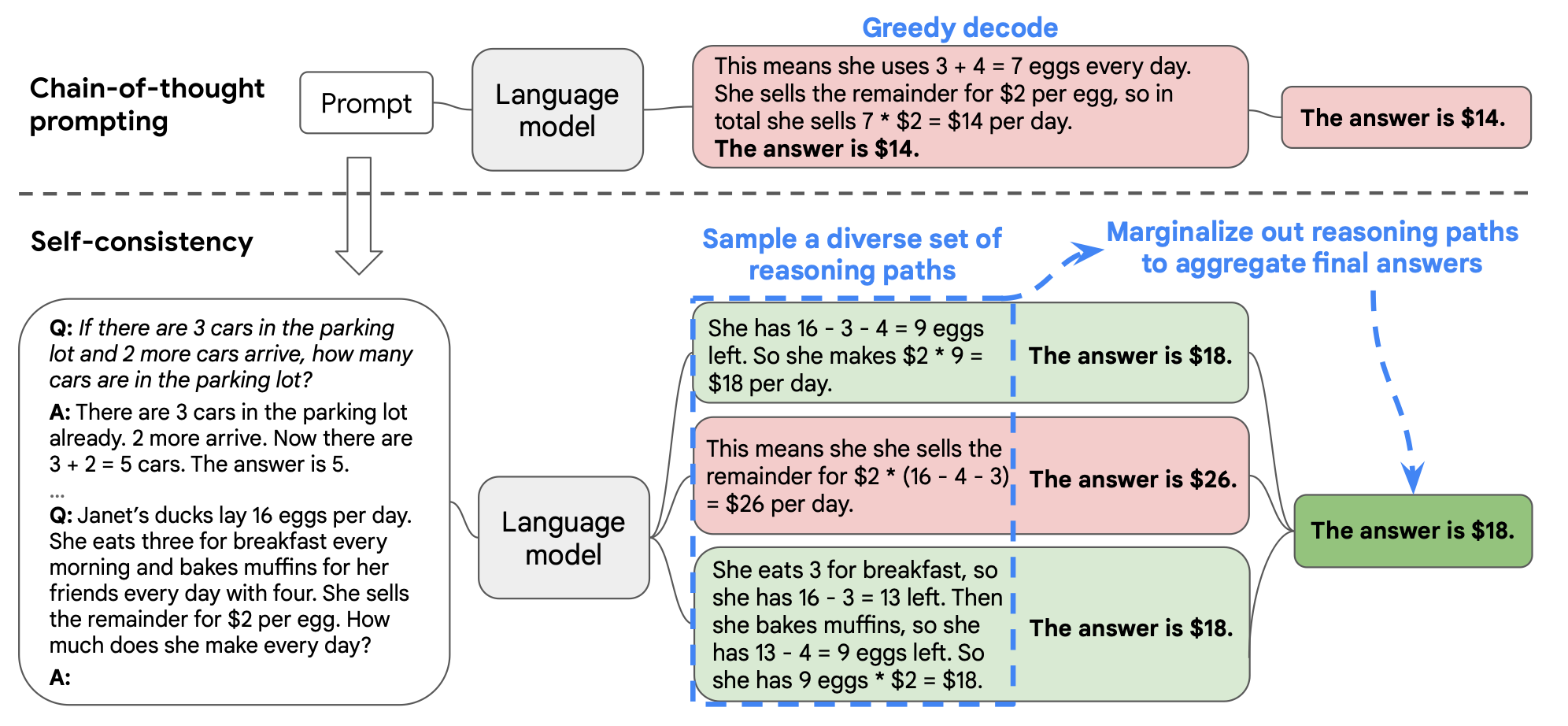
L’auto-cohérence simule la pensée humaine, qui implique la capacité d'évaluer différentes options avant de prendre une décision. D’une certaine manière, cela peut également être vu comme une forme d’intelligence collective, car seule la réponse la plus commune ou cohérente est considérée comme correcte.
L'étape finale d’agrégation et de sélection de la réponse correcte peut être effectuée à l’aide d’un algorithme standard ou par un LLM lui-même. Cette dernière approche est connue sous le nom de Universal Self-Consistency.
L’approche de l’arbre des pensées peut être considérée comme une méthode hybride qui combine le raisonnement séquentiel de la chaîne de pensée avec le traitement parallèle de l’auto-cohérence. Cette technique permet au modèle d’explorer simultanément plusieurs branches de raisonnement tout en maintenant une progression structurée à travers chaque ligne de pensée.
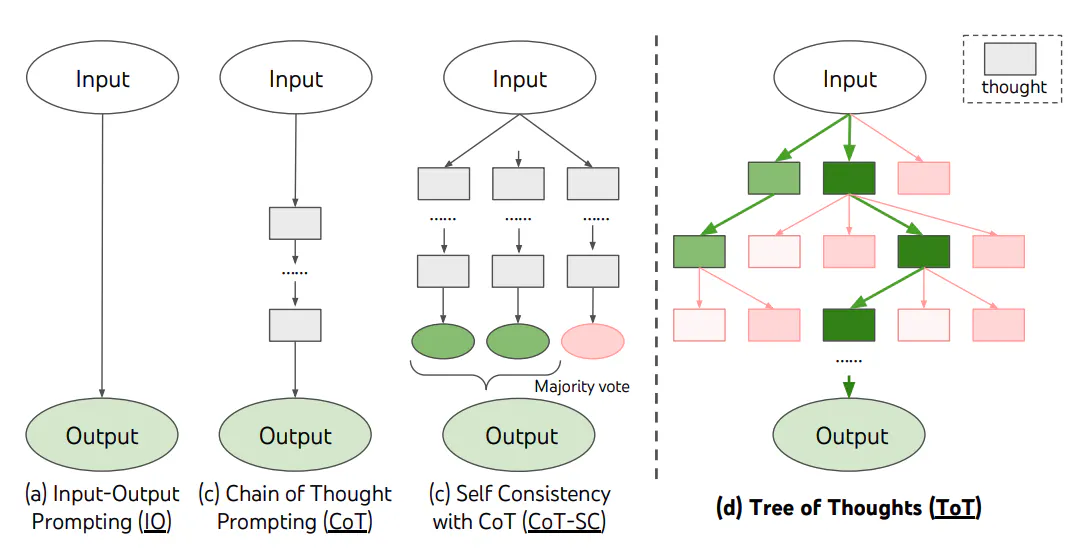
Les expériences montrent que l’Arbre des pensées améliore considérablement les performances sur des tâches nécessitant de la planification ou de la recherche, telles que le jeu de 24, l'écriture créative et les mini mots croisés.
Par exemple, selon l’article de recherche “Tree of Thoughts: Deliberate Problem Solving with Large Language Models”, alors que GPT-4 avec des prompts de chaîne de pensée n’a résolu que 4 % des tâches, la méthode de l’arbre des pensées a atteint un taux de réussite impressionnant de 74 %.
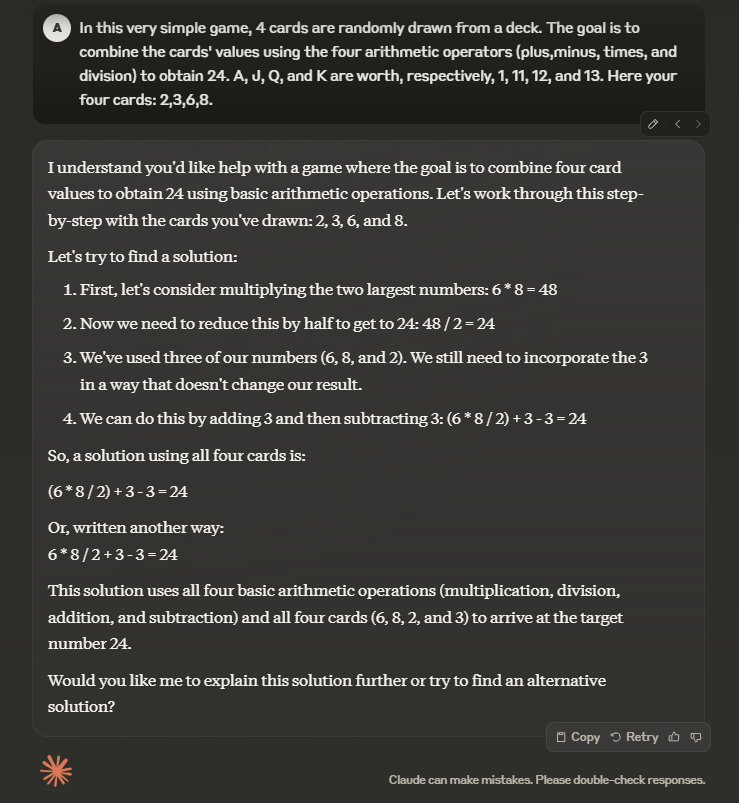
Bien que le prompting en zéro-shot n’ait pas pu donner la bonne solution, nous vous encourageons à essayer un prompting en Arbre des pensées plus complexe. Voici un exemple de la manière de structurer votre prompt :
Imaginez trois experts hautement intelligents travaillant ensemble pour répondre à une question.
Ils suivront une approche d'arbre des pensées, où chaque expert partage son processus de pensée étape par étape.
Ils tiendront compte des contributions des autres, affineront leurs pensées et s'appuieront sur les connaissances collectives du groupe.
Si un expert se rend compte que sa pensée est incorrecte, il le reconnaîtra et se retirera de la discussion.
Continuez ce processus jusqu'à ce qu'une réponse définitive soit atteinte.
La question est...
Dans ce jeu très simple, 4 cartes sont tirées au hasard d'un paquet.
Le but est de combiner les valeurs des cartes en utilisant les quatre opérateurs arithmétiques (addition, soustraction, multiplication et division) pour obtenir 24. A, J, Q et K valent respectivement 1, 11, 12 et 13.
Voici vos quatre cartes : 2, 3, 6, 8
Dans notre exemple, en utilisant le prompt donné, Claude 3.5 a commencé par adopter trois personnalités différentes (je sais que cela peut sembler étrange) avant d’arriver à la bonne réponse.

Dernier point mais non des moindres, le modèle de persona. Je l’ai réservé pour la fin car c’est le plus divertissant ! La première fois que j’ai utilisé ce modèle, j’ai demandé à ChatGPT de jouer le rôle de Jesse Pinkman de Breaking Bad, et c'était absolument hilarant.
Le modèle de persona est une technique utilisée pour attribuer un rôle ou une personnalité spécifique pour guider les réponses du modèle. Vous pouvez inciter le modèle à adopter diverses personnalités, telles que :
Cette approche aide à adapter les réponses du modèle pour qu’elles soient plus pertinentes et en accord avec le ton ou le type d’information souhaité, améliorant ainsi l’interaction globale et la rendant plus engageante.
Dans notre cas, nous avons expérimenté cette approche—découvrez les résultats par vous-même :
Un exemple de persona historique
En résumé, l’ingénierie des prompts englobe diverses techniques pour améliorer les interactions avec les grands modèles de langage. Du prompting en zéro-shot et en few-shot à la chaîne de pensée, à l’auto-cohérence, à l’arbre des pensées et au modèle de persona, chaque méthode offre des avantages uniques pour générer des réponses pertinentes et précises.
À mesure que les LLM continuent d'évoluer et de devenir plus puissants, il peut y avoir des cas où des prompts complexes ne sont pas nécessaires. Cependant, comprendre et tirer parti de ces techniques peut améliorer considérablement la qualité de vos interactions, les rendant plus engageantes et efficaces.