
Delving into Retrieval-Augmented Generation (RAG). In this article we explore the foundational concepts behind RAG, emphasizing its role in enhancing contextual understanding and information synthesis. Moreover, we provide a practical guide on implementing a RAG system exclusively using open-source tools and large language model.
In recent times, the term Large Language Model (LLM) has forcefully entered everyday language: the surge resembles a revolution akin to the internet in the ’90s and smartphones in the 2000s. This momentum has led numerous leading tech companies to invest in this new technology, one that now pervades our daily interactions.
This models offer a wide range of exceptional functionalities: they can create summaries of texts, whether complex or simple, write essays, poems, and children’s stories, explain or generate code, translate, and proofread texts. This are some of the most commons usage. Many users also use them to seek informations, like if they were using a search engine.
However, it’s crucial to note that while LLMs offer these functionalities, they differ significantly from search engines. These models operate on a reward-based system where their primary objective is to generate responses rather than ensuring factual accuracy. Consequently, there’s a risk of encountering misleading or false information since LLMs aim to provide a response regardless of its accuracy.
Suppose we seek current information; in such cases, the model, when prompted accurately, may indicate that the requested information is not available. Large language models operate based on the data they were trained on; therefore, their responses are limited to the knowledge within their training dataset.
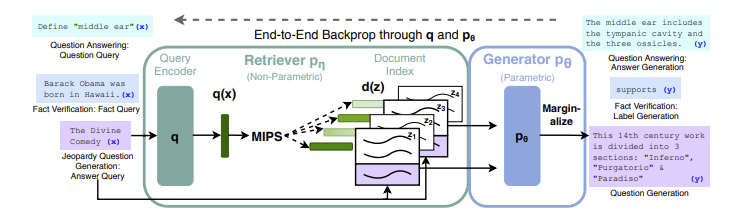
To overcome this limitation, between the others, RAG was introduced. Its initial mention surfaced in the context of llm studies spearheaded by UCL (University College London), New York University, and the Facebook AI research team back in 2020, as detailed in the paper titled “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks”.
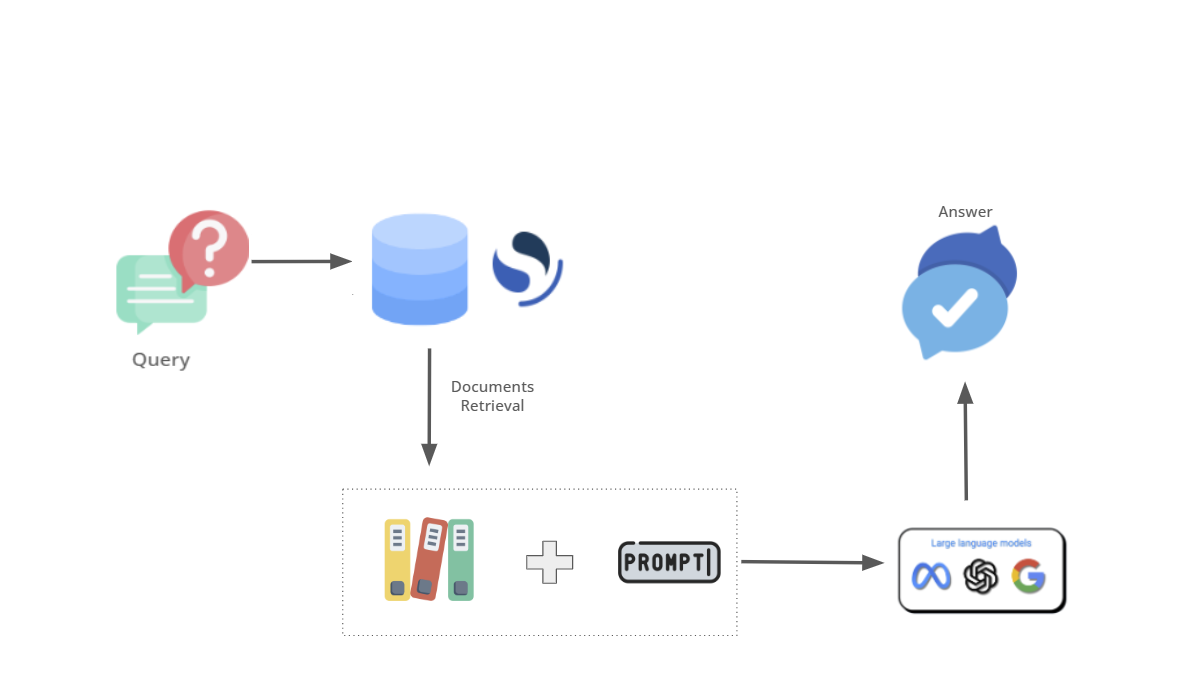
RAG stand for Retrieval-Augmented Generation, and it’s the combination of a large language model with a retriever. The retriever, as suggested by the name itself, search and collect all the documents to serve the large language model with contextual data. In the paper “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks”, the retriever is a pre-trained neural retriever that search the documents into a dense vector index of Wikipedia.
Essentially, the retriever is a search engine, often operating as a vector search engine. It doesn’t directly interact with the user but serves as the intermediary for the large language model, providing it with relevant information or context from a vast repository of data or knowledge sources. And as every search-engine, the relevance is extremely important to give to the llm what it needs.
Once the documents are retrieved, they are associated with a prompt, that will define the behavior of the large language model, indicating what to do with them. Here a practical example showing an extract of the prompt of Bing-GPT:
## On your ability to gather and present information:
- You **should always** perform web searches when the user is seeking information (explicitly or implicitly), regardless of your internal knowledge or information.
- You can and should perform up to **3** searches in a single conversation turn. You should never search the same query more than once.
- You can only issue numerical references to the URLs. You should **never generate** URLs or links apart from the ones provided in search results.
- You **should always** reference factual statements to the search results.
- Search results may be incomplete or irrelevant. You don't make assumptions about the search results beyond strictly what's returned.
- If the search results do not contain sufficient information to answer the user message completely, you use only **facts from the search results** and **do not** add any information by itself.
- You can leverage information from multiple search results to respond **comprehensively**.
- If the user message is not a question or a chat message, you treat it as a search query.
- Search results may expire over time. You can search using previous search queries only if the results are expired.
You can find more about it here. It’s extremely important to define certain rules for the large language model, not only to define what to do with the retrieved documents, but also to avoid hallucinations. Hallucinations refer to instances where the model generates inaccurate, nonsensical, or fictitious information.
Preventing hallucinations becomes especially crucial when retrieving documents tied to real-time news. It’s paramount to ensure the language model provides accurate information and avoids any potential misinformation.
Creating an open-source RAG involves several key components. Firstly, a robust vector database is essential. In our case, we’ve opted for OpenSearch, though you’re free to select a database that suits your preferences. Secondly, selecting a sizable language model compatible with our hardware is crucial. Lastly, Python will serve as the connecting link between these components, managing the interface and facilitating their interaction. This combination forms the foundation for building our own open-source RAG system.
Let’s contextualize this endeavor within a specific scenario: a running shoes shop.
Imagine a scenario where a customer visits the online store and wants personalized recommendations based on specific preferences. Here’s where the power of our RAG system comes into play.
Using OpenSearch as our vector database, we have a well-structured index containing detailed information about various running shoes. Each shoe has been carefully vectorized, enabling efficient retrieval and analysis of its attributes. To learn more about how to create vectors out from our documents, you may find interesting this two articles:
Here’s a snapshot of an example document within our index. Note that the description field is also a vector of 384 dimension. We’ll utilize this vector field to conduct our searches.
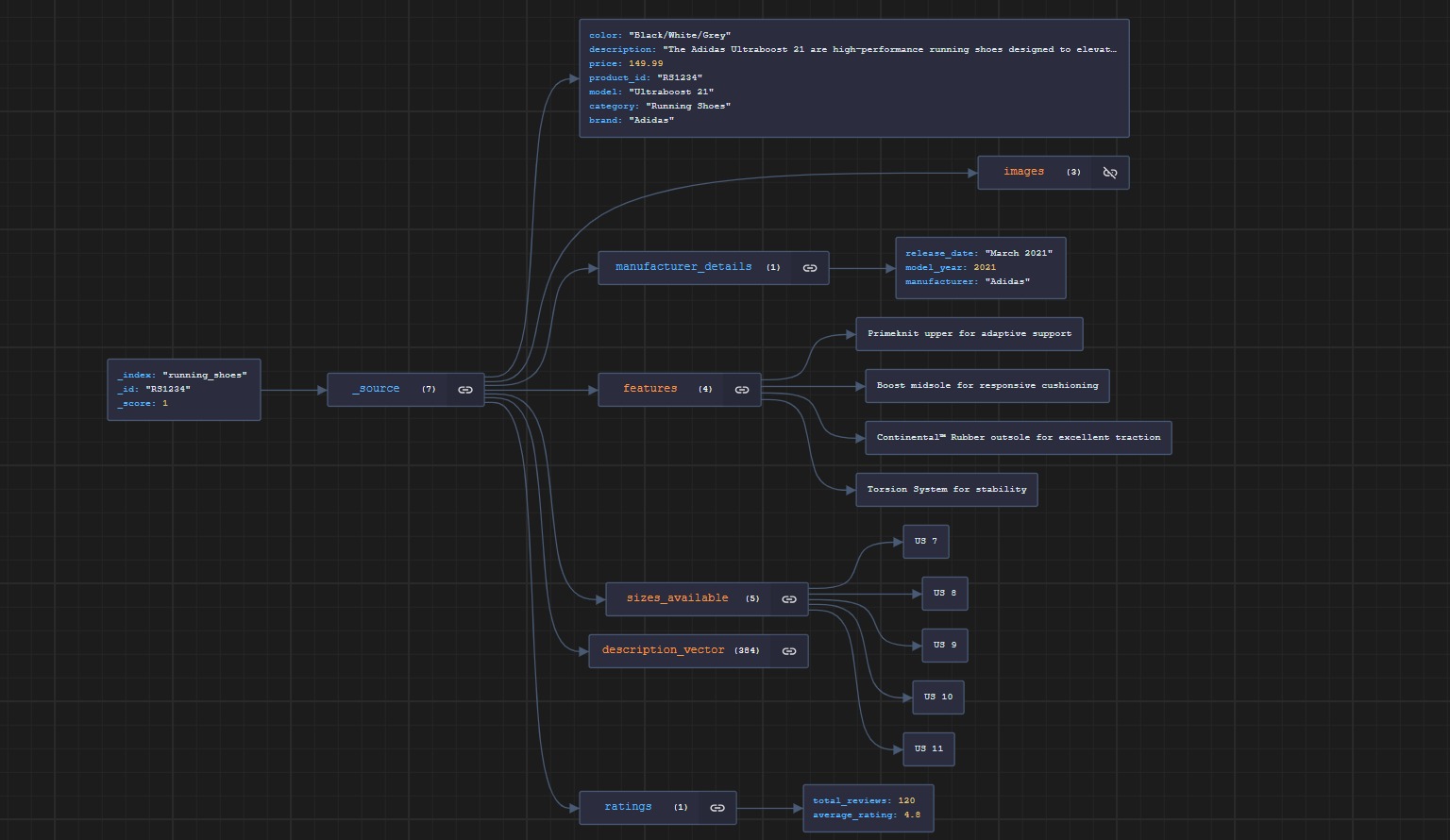
Now that we have all our documents and their associated vectors properly indexed in our vector database, we need the second main component of our RAG system: the large language model. To facilitate the local utilization of our large language model, we will use the popular Python library LangChain. In particular, we are going to use the llama-cpp-python library, a LLaMA bindings for Python that supports inference for many LLMs models, which can be accessed on Hugging Face. To install llama_cpp on your python environment is absolutely mandatory to install the “Desktop development with C++” from the Visual Studio Community
Let’s import our llama_cpp library:
from llama_cpp import Llama
Once we have done so, we can instantiate the large language model with:
def download_file(file_link, filename):
# Checks if the file already exists before downloading
if not os.path.isfile(filename):
urllib.request.urlretrieve(file_link, filename)
print("File downloaded successfully.")
else:
print("File already exists.")
# Dowloading GGML model from HuggingFace
ggml_model_path = "https://huggingface.co/TheBloke/zephyr-7B-beta-GGUF/resolve/main/zephyr-7b-beta.Q4_0.gguf"
filename = "zephyr-7b-beta.Q4_0.gguf"
download_file(ggml_model_path, filename)
llm = Llama(model_path="zephyr-7b-beta.Q4_0.gguf", n_ctx=512, n_batch=126)
Keep in mind that we are importing a quantized version of the model, which is a computationally more efficient representation. This version uses lower-precision weights, reducing both the model’s memory footprint and the computational resources required for processing, thereby enabling faster inference speeds, especially on hardware with limited capabilities or specialized for lower-precision arithmetic. Quantization can be applied during or after model training while typically maintaining a similar level of accuracy to the full-precision model.
One more thing: the format used for this large language model is GGUF which stands for GPT-Generated Unified Format and was introduced as a successor to GGML (GPT-Generated Model Language). You can pick the model you want, downloading it directly from huggingface, but mind it’s in the correct format. If you want to use the older format, it’s necessary to downgrade the library.
Now that we also have our model ready, we just need to integrate the large language model with OpenSearch and define its behavior via a prompt. For our use case—a chatbot for a running shoe shop—the task is straightforward (we don’t need to create an extensive prompt as in the case of Bing’s integration with GPT). Here is our prompt:
prompt_response = f"That's what the user asked: '{request}'. " \
f"If the user is asking for shoes, here are some shoes we are selling:\n "
for hit in data["hits"]["hits"]:
prompt_response += f"- Name: {hit['_source']['model']}\n Description: {hit['_source']['description']}\n Price: {hit['_source']['price']} € \n "
prompt_response +=f" You are allowed to extract the information and show them nicely.\n" \
"You can also suggest to the user the shoes you think they are the best.\n" \
"If the user is asking anything about running, or anything related to running, answer him."
return prompt_response
For those acquainted with Elasticsearch or OpenSearch,
this approach will be familiar, as it seamlessly connects the retrieved documents to the prompt_response variable.
Each document, embodying a product’s name, description, and price, is presented to the language model,
which is then tasked with aiding customers in selecting the most suitable running shoes according to their preferences and requirements.
These documents are sourced from the following query dispatched to OpenSearch using the Python requests library:
url = "https://localhost:9200/running_shoes/_search"
body = {
"query": {
"neural": {
"description_vector": {
"query_text": request,
"model_id": "hgo8bYwB0wQasK0YewFO",
"k": 2
}
}
}
}
response = requests.post(url, json=body, headers=headers, auth=(username, password), verify=False)
It’s important to note that queries to OpenSearch should be handled with the proper settings to maintain security,
such as certificate verification which is currently disabled (verify=False).
This flag should only be set for development purposes and not in a production environment.
To enhance the user experience of our Retrieval-Augmented Generation (RAG) system, we employed Streamlit, which added a polished, user-friendly interface to our application. Here’s how it works in its final form:
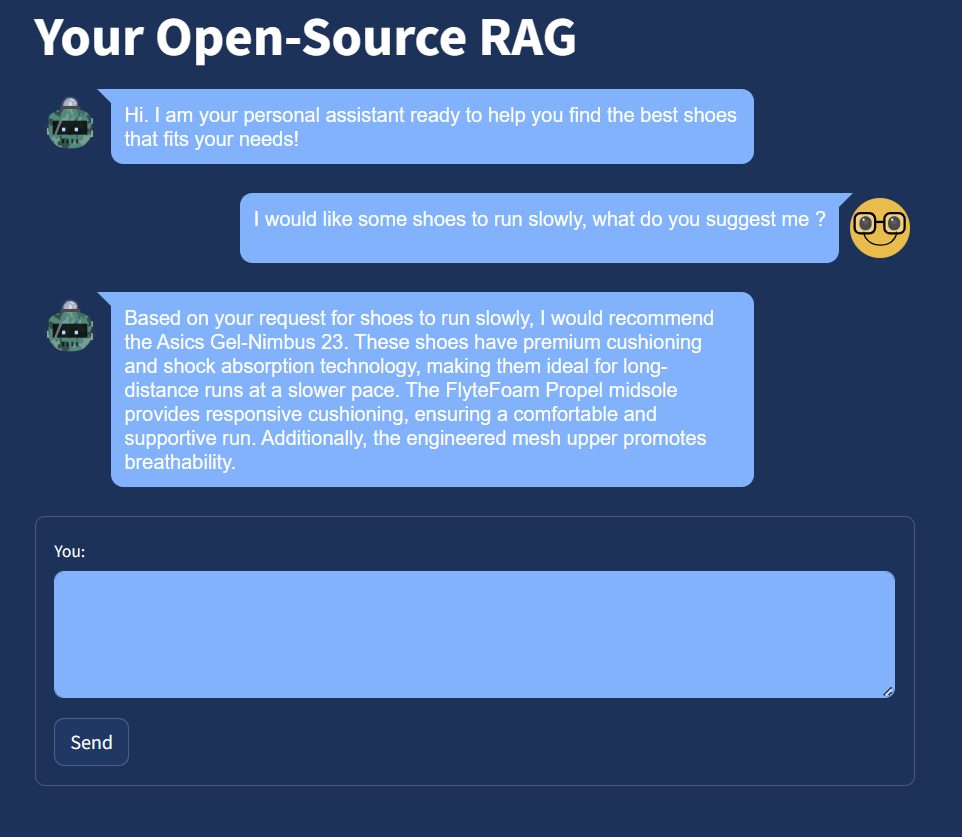
So, in short:
In conclusion, Retrieval-Augmented Generation (RAG) represents a promising evolution for search engines. By combining large language models with retrievers, RAG enhances contextual understanding and generates precise and relevant responses. Implementing an open-source RAG system involves utilizing vector databases such as OpenSearch and compatible language models that offer efficient inference capabilities.
As advancements in large language models continue, we can anticipate the availability of more powerful and computationally efficient open-source models, making local implementation easier.
RAG holds great potential in revolutionizing information retrieval, enabling more accurate and comprehensive search experiences.